When crows join your LiveKit call
What LiveKit Data Tracks Could Make Visible

I was standing near my front yard in Sonoma County in 2024 when I looked up and saw two things on the same oak branch that should not have been on the same branch.
A hawk was hunched over its meal, working at it with that focused, head-down posture hawks take when they are eating. A few feet to the right, on the same horizontal limb, a crow stood upright in full view.
Not mobbing.
Not threatening.
Standing.
And talking.
For at least thirty seconds — I know because I started filming on my phone — the crow vocalized and moved almost continuously. Not the broadband caw a crow uses when it is announcing or alarming. Something softer, more varied, more intimate. Rattles, coos, wheedles, mutters. The kind of vocal range a crow normally uses with another crow it knows.
It leaned forward into some phrases as if to put itself in front of the hawk’s vision, then leaned back.
I’m here. I’m here. Be a good hawk. Help a poor crow out.
The hawk occasionally glanced over at the crow, but it kept eating. The deliberate nonchalance was its own kind of statement: power expressed as indifference.
I stood there with my phone up, watching this small interspecies negotiation play out, and I wondered what I was missing. The proximity was unusual. The vocal register was unusual. The whole posture of the encounter was unusual.
Why would the crow expect the hawk to share? Was there some history between them? Some quid pro quo I did not know about? Or was the crow simply opportunistic, and I was projecting structure onto what was really just a hungry bird trying its luck?
After another minute the hawk finished its meal. The crow flew off with a few sharp caws — the first conventional crow vocalizations in the whole encounter. The hawk preened itself briefly, then it left too. I lowered my phone and put it back in my pocket.
What I had captured was a video.
What I wanted was an annotation layer over reality.
That is the interesting thing LiveKit data tracks make possible: not just more data inside a room, but interpreted data returning to the room as a first-class stream.
What the phone could have shown me
Suppose, two years later, I record the same encounter — same yard, same branch, same birds — but with the phone running an agent-equipped LiveKit room.
The phone is publishing two tracks: video from the rear camera and audio from the mic. An AI agent has joined the same room. Not a chatbot. A peer.
It subscribes to both tracks the moment they appear, runs them through a pipeline I will describe in a minute, and starts publishing its own track back into the room: a third kind of track, one that does not carry audio or video. It carries structured frames: bounding box coordinates, timestamps, classification labels, confidence scores, and recent behavioral context.
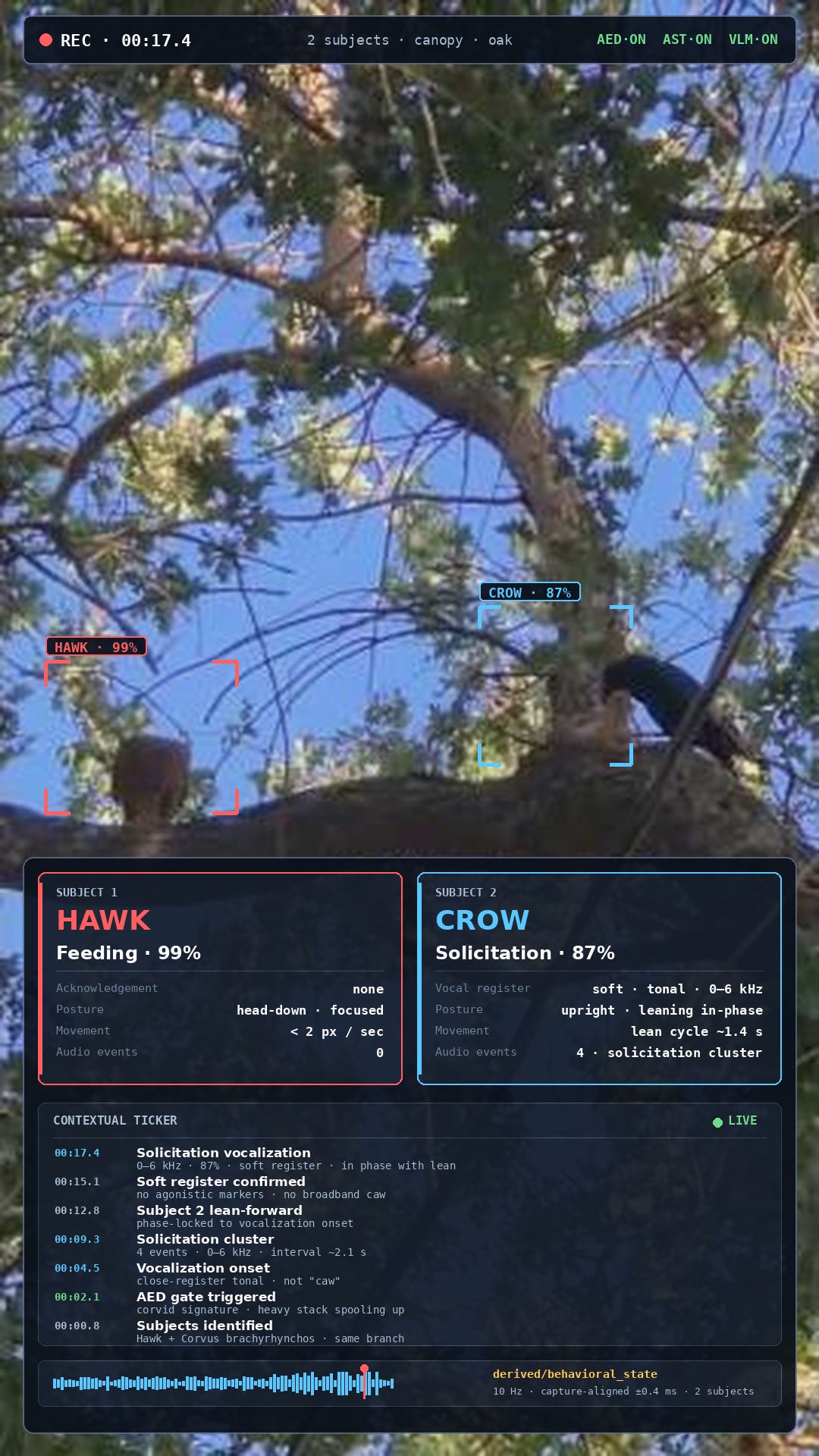
My phone’s renderer subscribes to that track and draws an AR overlay on top of the live camera view.
A red box locks onto the hawk. A blue box locks onto the crow. Tethered labels appear.
The crow’s box reads:
Solicitation vocalization — 87%
The hawk’s reads:
Feeding — 99%
Acknowledgment: none
A contextual ticker scrolls along the right edge:
Solicitation cluster, 4 events
Soft register
No agonistic markers
Subject 2 leaning forward in phase with vocal phrases
When the crow finally flies off and emits its conventional caws, the ticker flips:
Behavior shift
Standard contact call
Solicitation ended
None of this would have told me whether the crow and the hawk knew each other. None of it would have told me whether crows historically beg from raptors in this area, or whether this was a one-off.
But it would have told me, while I was standing there with my phone up, that I was not imagining things. The crow’s vocal register really was different from a caw. The pattern really was solicitous rather than mobbing. The hawk really was performing indifference.
The questions I came home with would have been better questions.
That is all the AR overlay is offering.
Not translation.
Annotation.
The crows, of course, did not know they had joined a video call. But they had. Their vocalizations and their movements arrived at the agent through my phone, the agent interpreted them, and the interpretation came back to my screen in real time.
The architecture does not care that the participants are crows.
The room is the architecture.
They are just publishing tracks.
Why this works now
Three primitives have to be in place for this to feel natural.
The first is already familiar: AI agents as first-class room members. LiveKit’s agents framework has been letting you drop a conversational agent into a room for a while now. The agent subscribes, processes, and publishes using the same conceptual room model as a human participant.
The second primitive is newer: data tracks. LiveKit recently shipped data tracks, and the announcement frames them around robotics, teleoperation, sensor fusion, telemetry, and other high-frequency data streams. That framing is correct, but it understates what the primitive is doing.
A data track is a stream of binary frames published by one participant and forwarded by the SFU only to participants who subscribe. Each frame carries a 64-bit user timestamp, which means the application can stamp frames with their capture time at the source. There is no practical limit on the number of data tracks in a room; LiveKit cites a theoretical limit of 65,535, which makes one-track-per-sensor a real design option rather than a cute diagramming trick.
The underlying transport is unordered and lossy in the right way for real-time streams: frames are delivered fresh rather than retried forever. Intermediate frames may be dropped under network pressure. That sounds like a limitation until you remember that with sensor streams, stale data is often worse than missing data.
Freshness beats completeness.
The third primitive is the one most people may miss when reading the data tracks announcement: an agent can publish derived data tracks back into the room.
The agent is not just a subscriber that ingests sensor data and writes to a database somewhere. It is a peer. It takes in raw tracks and emits new tracks — interpreted ones — into the same room, at the same temporal layer, available to any subscriber the same way the raw tracks are.
That third move is what makes the architecture compositional.
A specialist agent can produce a derived track. A second agent can subscribe to that derived track plus the raw audio and produce something further. A UI can subscribe to any subset. A researcher can subscribe to the whole messy firehose. A casual viewer can subscribe only to the video and the final annotation layer.
You assemble pipelines through room topology rather than through one monolithic agent.
The room becomes a shared temporal substrate where participants publish what they have, subscribe to what they need, and compose interpretations in flight.
The architecture, made explicit
Here is how the pipeline composes in the front-yard case.
The phone publishes two tracks: video at 30 frames per second from the rear camera and audio from the built-in mic. The agent subscribes to both.
An acoustic event detector — small, lightweight, and running continuously in the agent process — listens on the audio track and acts as a gate. While there is nothing interesting happening — wind in the oaks, distant traffic, the occasional dog — the heavy machinery stays cold.
The moment the detector hears a target signature, such as a corvid vocalization in the right frequency band, it spools up the rest of the pipeline.
The rest of the pipeline is two parallel inference paths.
The audio path runs an Audio Spectrogram Transformer trained on corvid behavioral repertoire. It consumes overlapping three-second windows and emits behavioral context embeddings: alarm, contact call, solicitation, post-aggressive descent, and so on.
The video path runs a lightweight vision model at one or two frames per second, producing bounding boxes and species classifications.
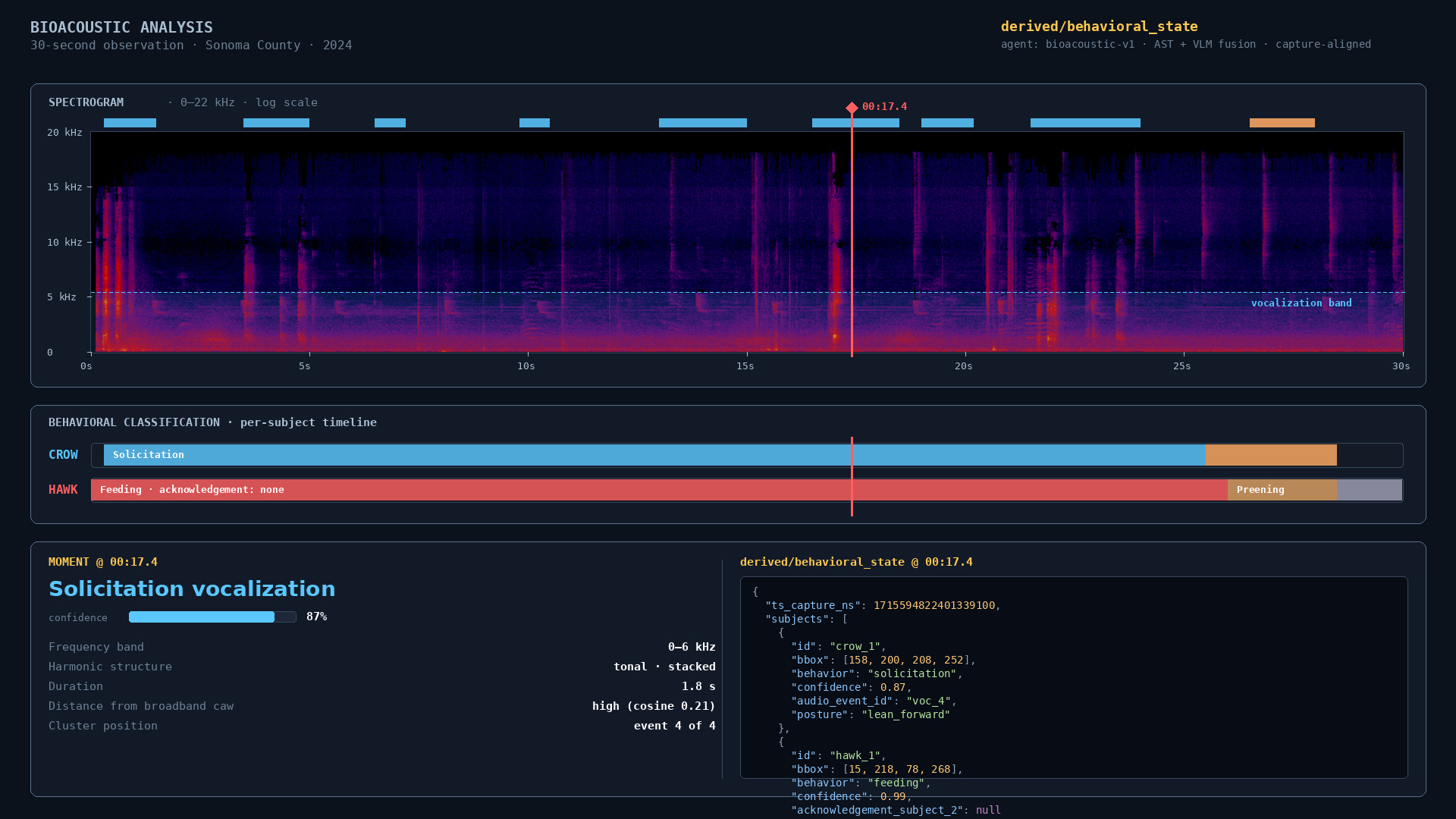
A fusion step reconciles the two streams. This is where capture-time timestamps stop being a footnote and start being the architecture.
The audio frame and the video frame can be aligned to their actual capture moment, not merely their arrival moment. Without that, the application is guessing across two pipelines with different latencies, potentially different clocks, and a network in between.
With capture-time timestamps, alignment becomes a tractable application problem instead of a guessing game based on arrival order.
The fused result is published back into the room as a behavioral_state data track at roughly 10 Hz. Each frame on that track contains the bounding boxes, species confidence, behavioral classification, classification confidence, linking timestamp, and a small ring buffer of recent context.
The phone’s renderer subscribes to that track and draws the overlay.
Drawn out, the architecture looks less like an app pipeline and more like a room full of publishers and subscribers.
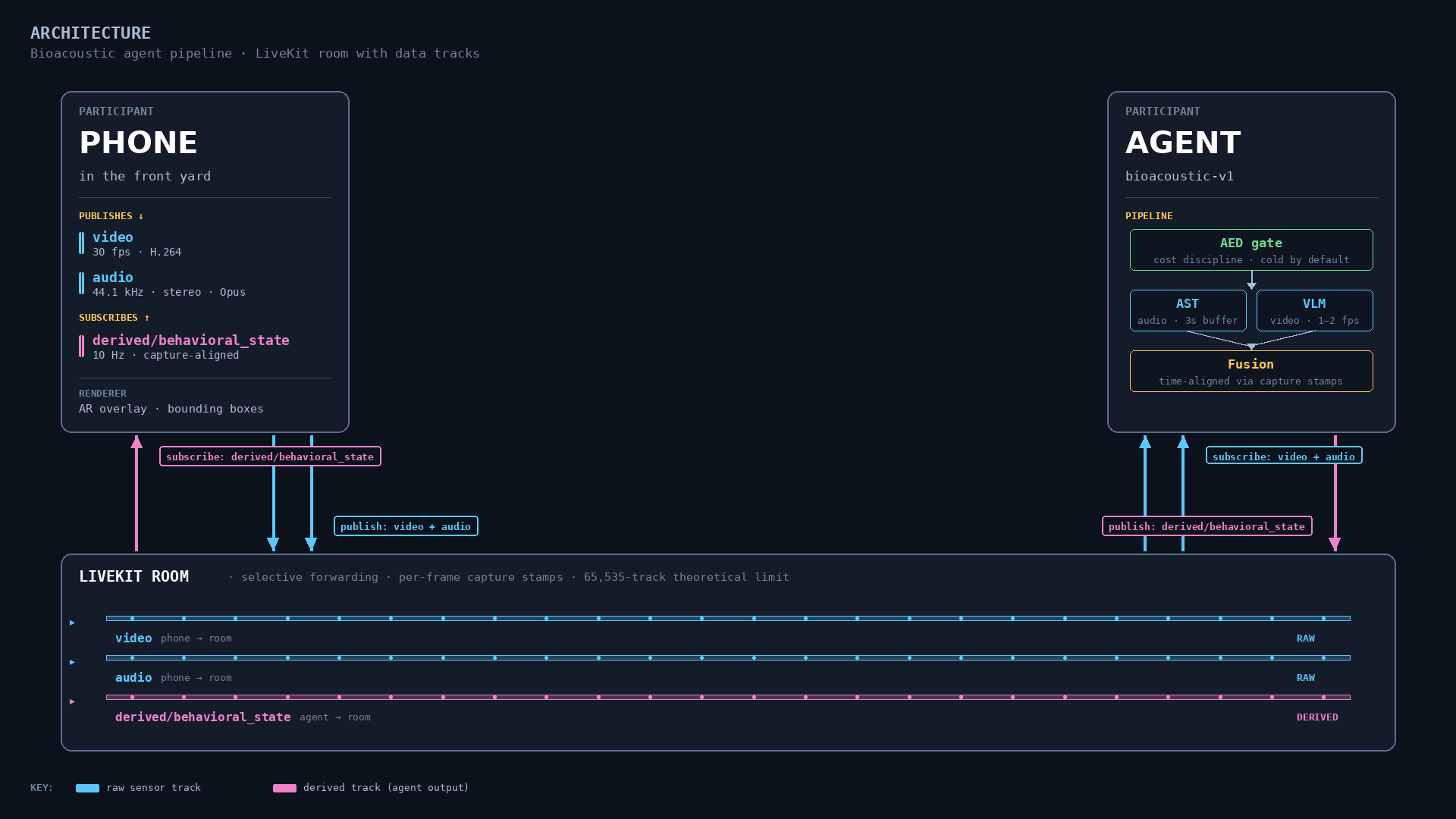
The structure has a few properties worth noticing.
The cost discipline lives in the acoustic event detector. Heavy GPU pipelines run only when there is something to interpret.
The bandwidth discipline lives in the SFU. Clients only pay for what they subscribe to.
A researcher’s full-fidelity client can subscribe to everything: raw video, raw audio, intermediate detections, model embeddings, and final derived behavior state. A casual viewer can subscribe only to the video and the derived track.
Same room.
Very different bills.
Same substrate, very different room
Let me put the crows down for a moment.
Same architecture, different participants.
A patient is sitting in her kitchen in Modesto. She is wearing a chest patch and a finger oximeter. Both are paired with her phone, which has joined a LiveKit room.
Her cardiologist is on the other end of the same room from a clinic in Stockton. Her daughter is dialing in from her office in Sacramento.
Three humans. Three video tracks. Three audio tracks.
Familiar.
What is less familiar is what else is in the room.
The chest patch is publishing its own data track: single-lead ECG at 250 Hz, respiration at 25 Hz, and accelerometer data for posture. The oximeter is publishing another: SpO2 and pulse rate at 1 Hz. A transcription agent is publishing a derived data track with the rolling clinical conversation segmented and tagged.
A triage agent is subscribed to all of the above and is publishing a derived clinical_concern track: a low-frequency stream of structured observations.
For example:
Ectopy increasing during patient’s account of stair-climbing event.
SpO2 nadir 91% during exertion description, recovers within 12 seconds.
Patient described “tightness”; intent agent uncertain whether somatic or emotional.
Ignore productization and regulatory approval for a moment. I am using medicine here because it makes the subscription-boundary problem obvious.
The cardiologist’s view subscribes to one combination of tracks. She sees the live ECG strip, the SpO2 trend, and the concern annotations layered onto the conversation transcript.
The daughter’s view subscribes to a different combination. She sees the video and audio of her mother and a softened summary of the agent’s findings: no raw waveforms, no alerts she might misinterpret.
The patient herself sees a deliberately simple view: her doctor’s face, a small reassurance indicator, and a button to pause the session and ask a question.
The same primitives that drew bounding boxes around the hawk and crow are drawing waveform annotations onto a conversation transcript.
The same fusion-by-capture-time that aligned audio and video in my front yard is aligning ECG against the verbal description that triggered it.
The same selective-forwarding economics that kept the bandwidth bill sane in the canopy case are letting three subscribers consume three radically different slices of the same room.
The agent is not translating the patient’s body to her, or to her doctor.
It is annotating.
It is saying: here is what your body did during this moment of your story.
That is the same posture the bioacoustic agent takes toward the crow.
Neither agent is claiming to speak for what it observes. Both are saying: here is structure I noticed; you decide what to make of it.
What the room actually is
The LiveKit room used to be easy to describe as a video conferencing primitive.
With data tracks and agents as peers, it is not really just that anymore.
It is a shared spatiotemporal substrate: a place where any sensing or acting entity can contribute streams that other entities can subscribe to, fuse across, and respond to.
The participants do not have to share a language. They do not have to share a sensory modality.
A crow vocalizing, a chest patch sampling, a phone framing, an agent inferring, a human watching, a UI rendering — these are all the same kind of thing, mechanically. Each publishes what it has. Each subscribes to what it needs.
The room is the manifold they all inhabit.
Calling this a phenomenological substrate is, I admit, philosophical hyperbole.
But not by much.
What is actually happening is that the room has become a structured environment in which perspectives meet: perspectives of very different kinds, weighted by their own subscription patterns, time-aligned by capture stamps, and composable through derived tracks.
It is a small phenomenology.
But it is a real one.
The room does not care who or what is doing the perceiving. It cares about tracks: what is published, what is subscribed, and when each frame happened.
There is something strange about realizing that the same primitive that lets you join a Zoom-equivalent meeting also lets a hawk join a research session it does not know exists.
The strangeness is the point.
The substrate is general because it does not ask what kind of thing you are. It asks what you publish and what you want to know.
Where this goes
The implications fan out further than I have room for here.
The convergence of conversational AI and physical AI on a single substrate is the obvious one. Robots, drones, biologgers, medical devices, lab instruments, industrial sensors, and human collaborators can all become room participants under the same model as agents and humans.
Industrial monitoring fits this shape.
Ensemble performance fits this shape.
Distributed scientific instruments fit this shape.
Multi-party clinical care fits this shape.
Search and rescue fits this shape.
Anything that involves heterogeneous sensors, multiple observers, and the need for interpretation in flight fits this shape.
One short note on consent.
The moment biosensors enter the picture, the question of who can subscribe to what stops being a bandwidth optimization and starts being an ethics question.
The per-track subscription model is the right place to enforce those boundaries.
A patient’s raw ECG should be subscribable by the clinician and not by the daughter. A meeting participant’s stress estimate, if such a thing is ever published, should be subscribable by their coach and not by their employer. A research animal’s sensor stream, a worker’s biometric signal, a child’s location trace, a participant’s emotional-state inference — each one needs a boundary.
The substrate gives us a clean place to draw those lines.
We have to actually draw them.
Not translation.
Not mind-reading.
Annotation, published as a track.
That is the future-facing part.
The crow and the hawk are just the part that made me look up.